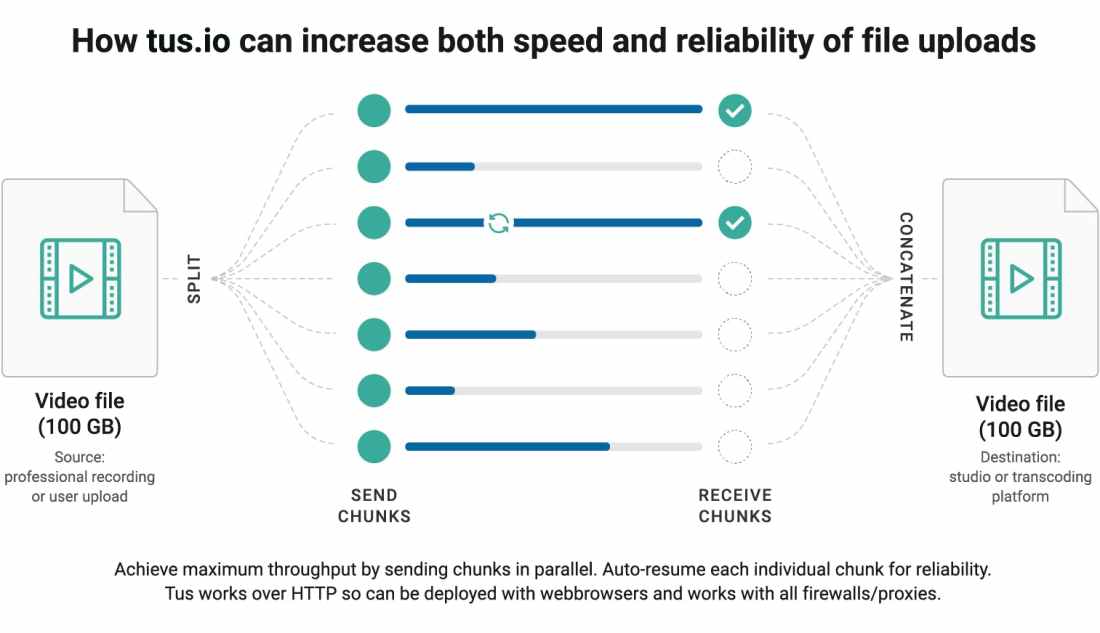
Not a single developer can live without using StackOverflow, almost daily 🙂, but should you care about building your reputation points on it? .. and how?
What is Reputation?
As per the official StackOverflow description for the reputation
Reputation is a rough measurement of how much the community trusts you; it is earned by convincing your peers that you know what you’re talking about. The more reputation you earn, the more privileges you gain and the more tools you’ll have access to on the site – at the highest privilege levels, you’ll have access to many of the same tools available to the site moderators. That is intentional. We don’t run this site; the community does!
The Why part
Well, it is a reputation, which tells a lot about you, like:
- How much the community trusts you
- How you are willing to give the community back
- Which specific set of technologies/frameworks are you interested in
- Which specific tag you got most of your reputation in (which is probably the most important thing)
- And even the way you communicate your thoughts in writing the answers, and how clear and concise are you
The How part
First let’s see what actions can give you the reputation points:
- question is voted up: +10
- answer is voted up: +10
- answer is marked “accepted”: +15 (+2 to acceptor)
- suggested edit is accepted: +2 (up to +1000 total per user) (when you get the privilege of reviewing/accepting other edits, you won’t get these points anymore)
- bounty related points (It is a rare thing, so let’s not focus on it)
but be careful, because you could also lose reputation when:
- your question is voted down: −2
- your answer is voted down: −2
- you vote down an answer: −1
- you place a bounty on a question: − full bounty amount
- one of your posts receives 6 spam or offensive flags: −100
Now concerning the strategy of getting the points, there are different types of people:
- The Legends
- The Moderator-like
- The Lucky
- The Addict
- The Hustler
- The Genuine (which is my way)
The Legends are reserved for people like Jon Skeet, who was the first to pass a One Million reputation points .. yes, you read it right .. one million 🙂.
The Moderator-like characters are like the pillars for the whole community, they keep it organized, they review every report/flag in there, & they care about moderating StackOverflow way more than just getting the reputation points, although they get a lot of points too 🙂.
The Lucky ones are the ones who got a ton of reputation on a simple questions like pupeno got 120k reputation from a single line question asking about the difference between “git fetch” & “git pull” .. yes that is it 🙈.
The Addict character is the person who opens StackOverflow almost everyday, seeking new questions in the fields he know, hoping he would be the first one to answer, which would give his answer a better opportunity in getting accepted or getting more up-votes, he is basically addicted to getting more and more reputation everyday.
They can even go all the way, doing every activity mentioned in this paper “Building Reputation in StackOverflow: An Empirical Investigation” like:
- answering questions related to tags with lower expertise density
- answering questions promptly
- being the first one to answer a question
- being active during off peak hours
- contributing to diverse areas
The Hustler is another addict character but his moral compass is not pointing north (If you know what I mean). This character will down vote rival answers no matter how better they are, just to give his answer the better exposure. The Character would also copy other answers with some slight modifications, just to get some up-votes out of it … Simply, Don’t be a Hustler.
The Genuine character, which is how I like doing things in an authentic way. For me this is the perfect balance between being passive (who doesn’t care about helping community) and being an addict (who wastes his/her own time contributing a lot in mostly an artificial way). For example, when I’m having a problem that I’m searching for its solution, I always keep an eye for all questions I find about this problem, specially the ones with poor answers or no answers at all, & when I find the perfect solution, here comes my time to add what I just found as an answer for all these related questions (whenever possible).

My genuine contributions led me to near 7K reputation points till now (2020), by just contributing when it is needed. The only problem with this approach is how to start, and how to be patient?!
My advice about how to start is as follows:
- Don’t be afraid to write a question or an answer, this is the only way you can get started
- Keep an eye on the badges section of your profile, because it is designed to let you track the badges that will help you familiarize yourself with the community & how contributions are being made, like the badge for making a certain number of up-votes, or the other one for up-voting questions more than answers and so on
- Keep an eye for questions you searched for, but didn’t like their answers, no matter how old they are, and no matter how many answers they have already, just give your own answer that you think it is better than the others
- Keep your questions/answers very clear, short and to the point, and use visual aids whenever possible
- Familiarize your self with the Markdown language, which will help you write better questions/answers on StackOverflow, & even on Github
Examples:
- I was making a chrome-extension where I needed to send a request to my server, it is easy to do it with jQuery’s
$.ajax(), but it is not available inside the chrome-extension, so I searched for how to make the request with just vanilla Javascript and saw this question for “How to make an Ajax call without jQuery“. Question already has about 20 answers, with 2 of them exceeding 200 upvotes already, but non of the answers where helpful to me, answers where very long trying to be perfect, and some of them even tried to add the full html needed to make the call (I don’t know why on earth would they do that), So after I found a very concise way of sending the request, I made this answer and now it became the 4th up-voted answer in that question with 104 up-votes and counting 😎 - I had a problem that my node server wasn’t logging the time for its error logs, I searched and reached this question about “How to add dates to pm2 error logs?” but the answer I found was a small one with no details whatsoever on how should this line work!
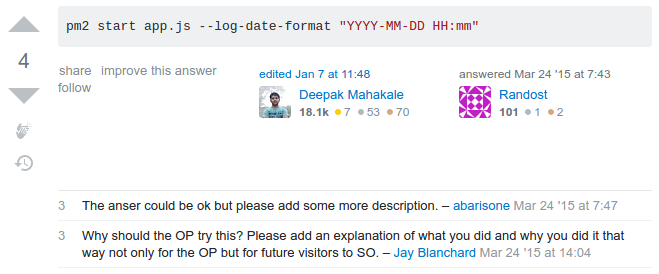
so, I searched through the library’s github repo & started digging until I found the exact issue & the exact commit where the logging feature was added to the library, so I added my own answer so I can add the needed details:
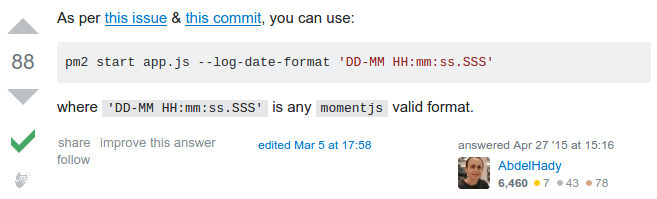
and the answer not only got accepted, but got 88 up-votes till now and counting 😎
Conclusion
- StackOverflow reputation is important for your career & personal branding.
- Don’t be afraid to ask a question or write an answer
- Be a Genuine contributor .. not a Hustler
- Contribute to the community, & it will trust you with reputation points 🙂